Vicent Pérez
AI Product Engineer
2 min de lecturaLinkedIn
RAG para cumplimiento normativo en suplementos
Hey! In today's post, I'll show you a recent project I worked on that demonstrates how #RAG applications can help companies avoid fines ⛔ 💸
In the supplements industry (proteins, creatine, vitamins…), compliance with regulations is critical. There are strict rules about what companies can and cannot say in product descriptions in their #webshops. As an example, let's focus on a creatine product description:
✅ Allowed: Creatine helps to improve performance during explosive strength efforts.
❌ Not allowed: Creatine stimulates/supports hormone production.
Failing to adhere to these regulations can lead to significant #fines. So, how can #LLMs help businesses stay compliant and avoid costly mistakes? Here's a simplified example showing how, using #Node.js, #Supabase, #LangChain, and #OpenAI we can achieve this.
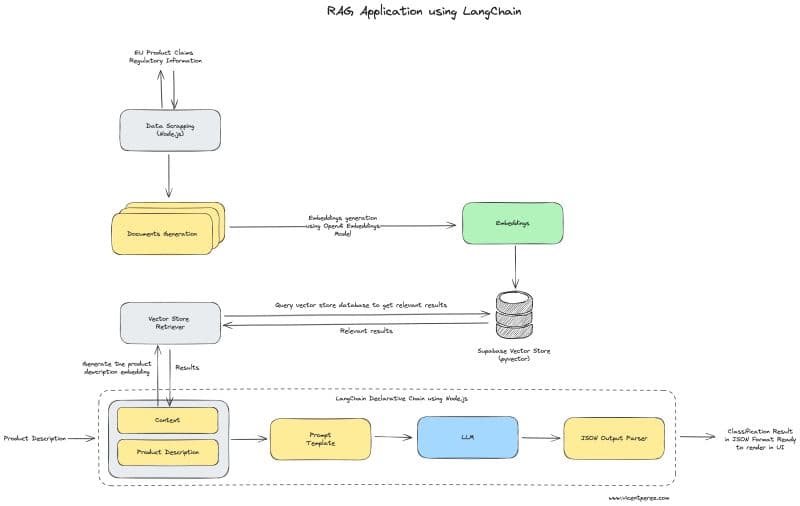
1️⃣ First, we need to gather the EU public regulatory data. As there is no API, we can do this by scraping using tools like Cheerio.js, a popular lib for web scraping in Node.js.
2️⃣ Once the data is collected, we need to process and structure it to create the embeddings. These embeddings can then be stored in a vector database, such as Supabase with the pgvector extension. If you are not familiar with those terms:
📌 An #embedding is basically a numerical representation of the data that captures its meaning for machine learning tasks.
📌 A #vectorstore is a specialized type of database designed for natural language queries. When a user inputs a query, the system searches the vector store for embeddings that closely match the input. We can use a method called cosine similarity, which measures the similarity between two vectors. After that, the system returns the most relevant documents for further processing.
3️⃣ Now that we have the claims data in Supabase, we can start creating the chain that is going to interact with the LLM. For this, we are going to use LangChain, a framework designed to build applications on top of LLMs.
4️⃣ This chain will have, as an input, a product description. The first step will be the embedding generation of this text to be able to query the vector database and retrieve related regulatory documents that align with the product description.
5️⃣ The retrieved documents are passed to the LLM as context, enabling it to determine if the description is compliant or if any changes are needed.
6️⃣ To ensure consistent and accurate results, we need to use a prompt template. This template will guide the LLM by clearly defining its role (as a regulatory compliance classifier), the desired outcome (result in JSON format), and any other relevant instructions.
✅ With this, we can automate the process of regulatory compliance checking or at least flag products that may require a manual double-check.
Hope you learned something new today
Stay tuned for more content, and if you need any help just drop me a message. 📩
Have a lovely day!
RAGwebshopsfinesLLMsNodeSupabaseLangChainOpenAIembeddingvectorstore