Vicent Pérez
AI Product Engineer
2 min de lecturaLinkedIn
DynamoDB y el reto de los reportes analíticos
Todo iba bien con DynamoDB... hasta que el equipo de analítica pidió un simple reporte...💥
Cuando piensas en arquitecturas serverless seguro que te vienen a la cabeza estos servicios: API Gateway, Lambda, EventBridge, SQS y.... DynamoDB?
Solo tienes que hacer una búsqueda en Google "arquitectura cloud serverless AWS" y verás que en el 90% de los diagramas aparece DynamoDB como servicio para la capa de datos.
DynamoDB es una base de datos NoSQL, clave-valor y documental, totalmente serverless y diseñada especialmente para:
- Realizar millones de lecturas / escrituras por segundo
- Tener bajas latencias
- Alta disponibilidad
- Escalabilidad automática.
- Bastante cost-effective
¿Esto suena genial, no?, pero, ¿es realmente DynamoDB una solución para todo?
Pues ya te voy avanzando de que no. A no ser que tengas muy claro los patrones de acceso a los datos.
Te voy a contar una anécdota.
Estábamos construyendo una aplicación con una arquitectura 100% serverless en AWS.
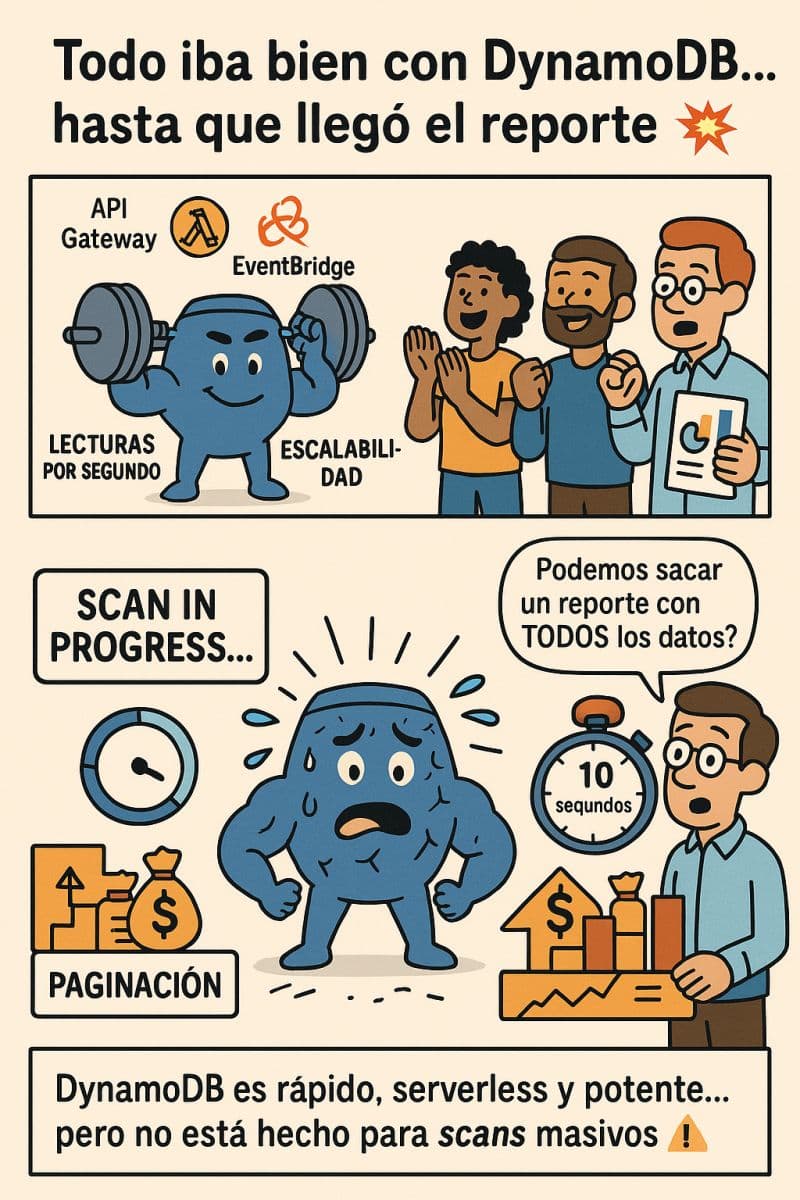
Todo iba bien: lambda para la lógica, API Gateway para los endpoints, EventBridge para el bus de eventos… y como no, DynamoDB como base de datos.
La app funcionaba de maravilla… hasta que surgió una nueva necesidad de negocio:
"Necesitamos cargar una serie de gráficas en base a TODOS los datos de la tabla pedidos (+100k registros)"
Parece simple, ¿verdad? Hacen falta todos los datos, vamos a hacer un Scan.
❌ Error
DynamoDB no está hecho para recorridos completos de tablas. Cuando haces un Scan, DynamoDB lee cada ítem uno por uno, sin usar índices.
- Es lento (nos tardaba aprox 10 segundos)
- Es caro
- Y no escala nada bien
Los índices en DynamoDB (GSI y LSI) están pensados para acelerar búsquedas cuando ya sabes cómo vas a filtrar los datos (por ejemplo, por tienda, usuario, estado, fecha, etc.). Pero no están diseñados para recorridos completos.
Y además, tienes que utilizar paginación, ya que hay un límite de 1MB por respuesta.
Lo que en una base relacional como AWS RSD PostgreSQL, harías un simple
SELECT * FROM orders;
Y dejarías que el motor se encargue de optimizar la consulta.
En DynamoDB, estás atrapado.
Podríamos montar un ETL y volcar datos a una base de datos de analítica, utilizando lambdas / DynamoDB Streams, o incluso exportarlos a S3 y consultarlos con Athena.
No obstante, esto añade más complejidad a la solución y es algo a tener en cuenta.
Así que, un fallo en el diseño de acceso a los datos o una mala decisión, te pueden penalizar en un futuro. Tenlo en cuenta.
DynamoDB es una herramienta potente, pero como toda tecnología, debe usarse conociendo bien sus limitaciones y en el caso de uso adecuado.
¿Y a ti, te ha pasado algo similar en alguna ocasión? Te leo